I'm a designer, game developer, and photographer.
Currently I work as a Director of UX at Shopify.
In the past I've worked at some amazing places—like Mozilla, Polar and Wattpad, after getting my start as a freelance consultant.
I'm also an entrepreneur and have built products like the hashtag manager Jetpack, the beautiful Muskoka: The Board Game, and created the award-winning, beloved indie game Lastronaut.
Selected Writing
Selected Work
Projects I've designed, directed or built from scratch.
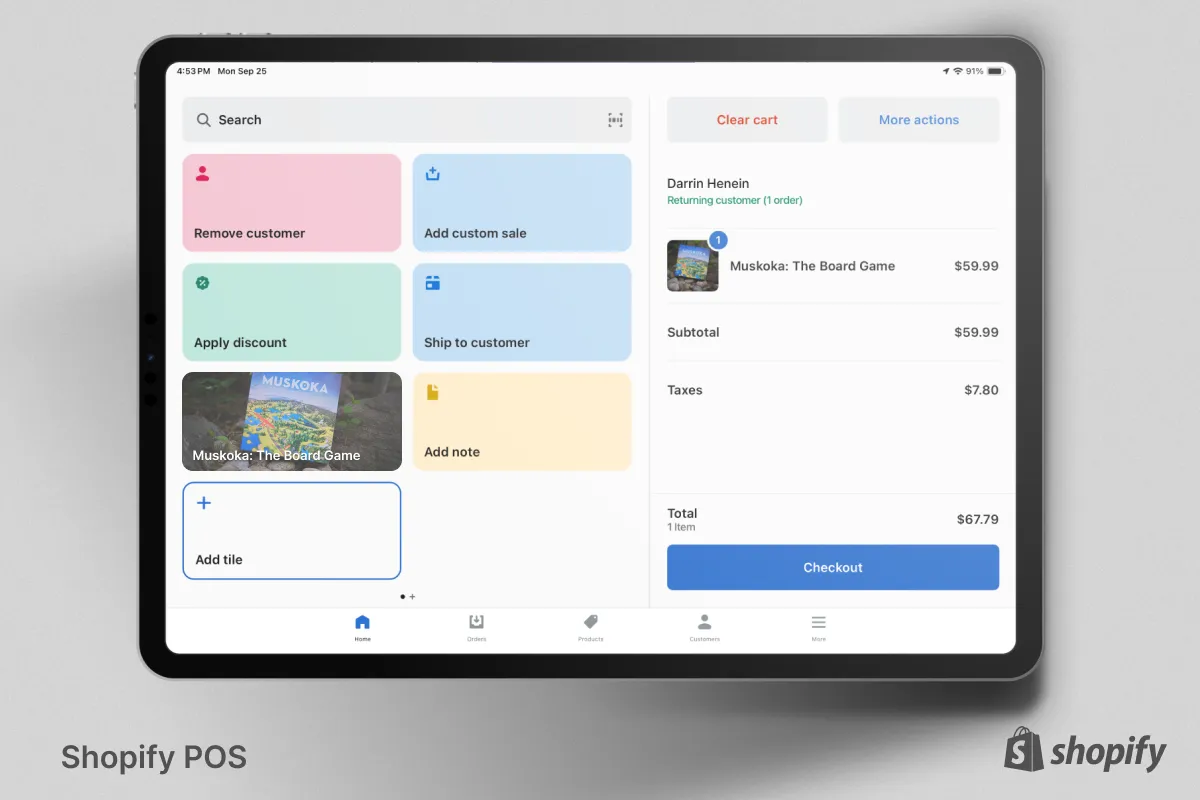
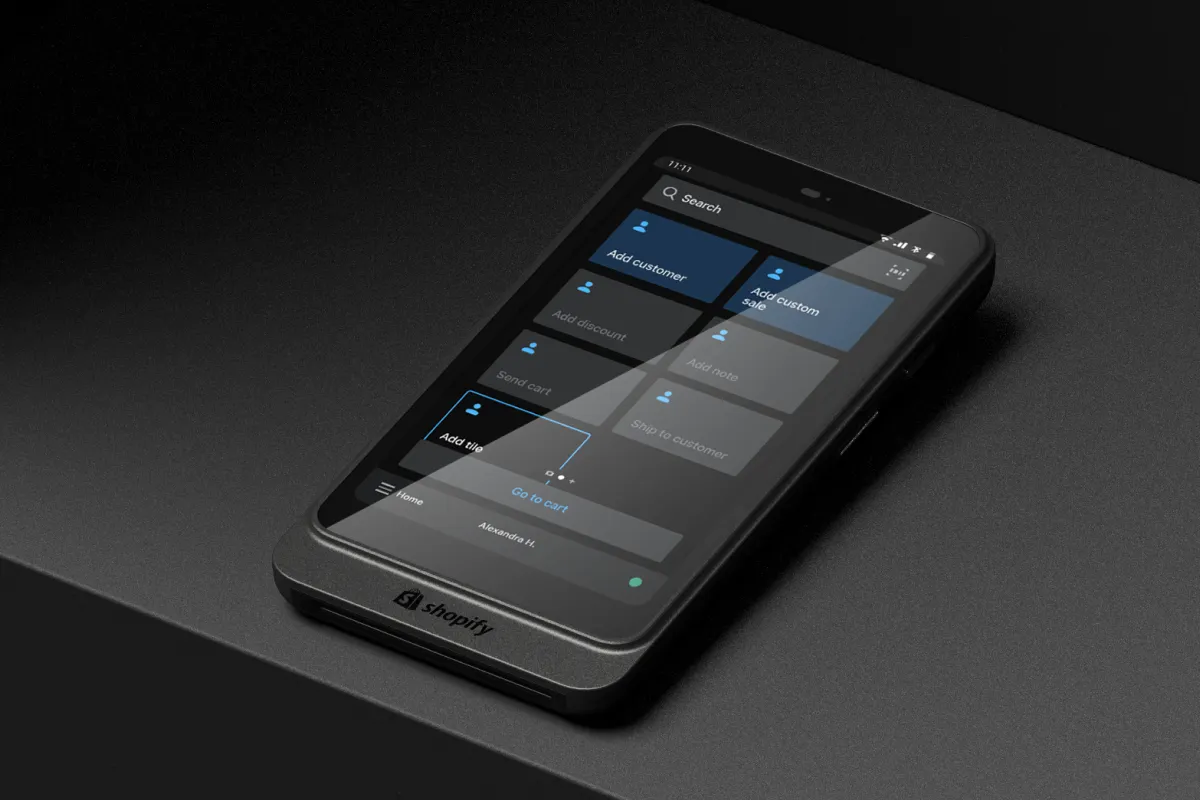
As the Director of UX for Shopify Retail, I built and led the research, product design and industrial design teams. I was responsible for the overall strategy, design and direction of our hardware and software experiences.











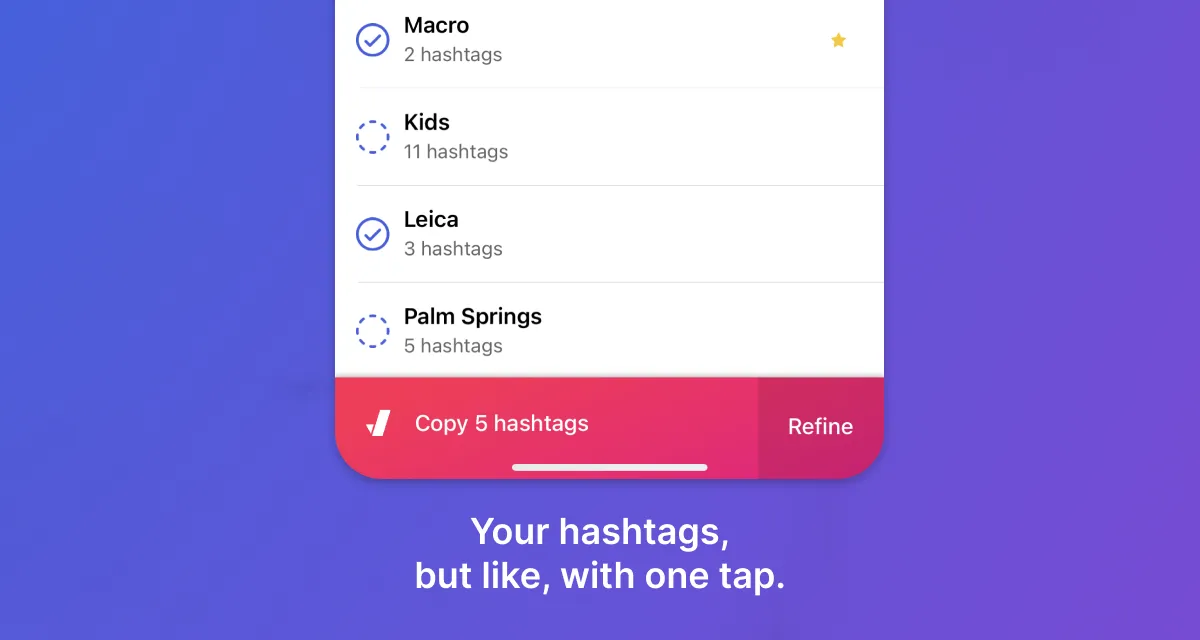
Jetpack is an app I built in Swift and SwiftUI, with a backend I wrote in Ruby on Rails.
All programming in Objective-C and C++ • Created all art, sound and music • Over 2M downloads • Awarded Apple's Editors' Choice • Nominated at the Canadian Video Game Awards



Experience
Featured Press
Two Ontario couples just created a board game that's a homage to Muskoka
blogTO ⇀
Lastronaut Is A Totally Free, Totally Addictive Endless Running Game For iPhone
TechCrunch ⇀
Move over Monopoly, Muskoka’s getting its own board game
Toronto Star ⇀
Inside Shopify UX
Anchor.fm ⇀
This Is the Golden Age of Indie Game Art
New York Observer ⇀
The Process Behind UX Design with Darrin Henein
MaRS ⇀